Skip to content
TL;DR
- 새로운 오픈소스 Agent ‘HUSKY’가 공개되었습니다. (메타, 앨런연구소, 워싱턴 대학 공동연구)
Introduction
- 2024년 6월 10일에 새로운 AI Agent가 발표되었습니다. (Meta AI, Allen Institute for AI, University of Washington)
- 오픈소스입니다
- 수치(numerical), 표(tabular), 지식기반추론(knowledge-based reasoning) 등 다양한 작업을 일관된(unified) 방법으로 수행하는 점이 특별하다(distinguished)고 얘기합니다.
Methodology
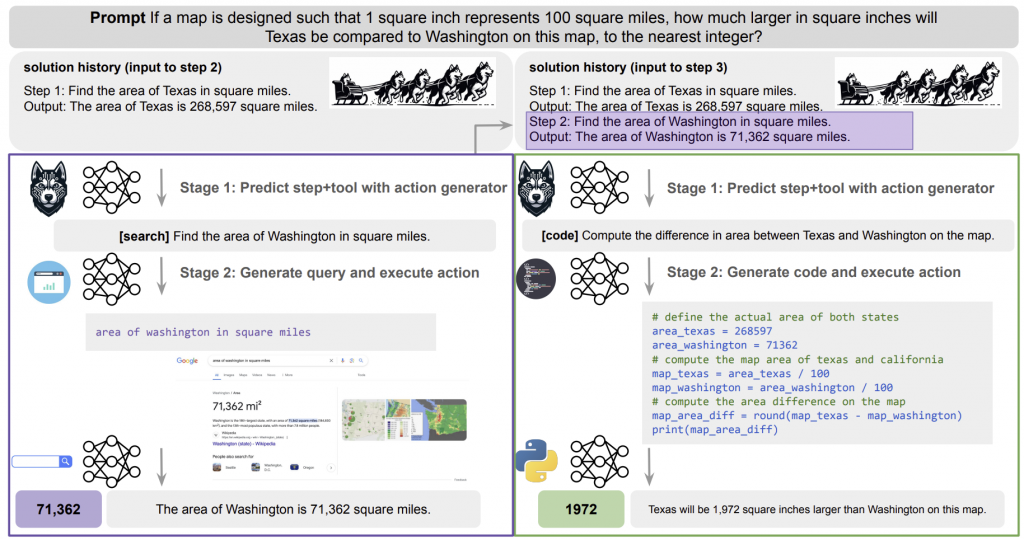
- Husky는 두가지의 작업을 반복적으로(iterative) 수행합니다.
- 계획(Action Generation) 단계에서는 프롬프트와, 현재까지 만들어진 답(solution)을 가지고 다음 action을 예측
- 실행(Action Execution) 단계에서는 계획된 action을 수행하고 solution을 업데이트
- action은 4가지 전문가 모델을 개별적으로 사용 (code, math, search, commonsense)’
- 모든 툴은 똑같은 입력 format을 받을 수 있고,
- math와 common sense는 바로 답변을 내놓으며,
- code는 코드 인터프리터에 대한 입력자료,
- search는 검색엔진 입력자료를 만들어냄,
- code, math, search 모델은 finetuned 모델이고, common sense는 그렇지 않음
Base Model
- Action Generator: LLaMA 2(7B, 13B), LLaMA 3 8B
- Code Generator: DEEPSEEKCODER-7B-Instruct-v 1.5
- Math Reasoner: DEEPSEEKMATH-7B-Instruct-v 1.5
- Query Generator: LLaMA 2-7B
Evaluation
- 14개의 평가 데이터셋에서 벤치마크 수행
- 수치 추론: GSM-8K, MATH, Google DeepMind mathimatics, MathQA 등
- 표 기반 추론: TabMWP, FinQA, TAT-QA 등
- 지식추론: HotpotQA, CWQ, Musique, Bamboogle 등
- 각 수치, 표, 지식 기반 추론은 다양한 오픈소스 에이전트와 비교함
- Few-shot prompted agents: REACT, REWOO, CHAMELEON
- Fine-tuned agents: FIREACT, LUMOS
- 혼합 도구(mixed-tool) 추론은 아래의 모델과 비교함
- REACT, LUMOS
- GPT 3.5 (turbo-0125), GPT 4 (0125-preview, turbo-0409, o)
Results
- 수치, 표, 지식 기반 추론은 모든 open-source 모델보다 성능이 우수함
- 혼합 도구 추론의 경우에는 OpenAI의 최신 모델인 GPT-4o 성능에 근접하며, IIRC 벤치마크에서는 GPT-4o보다 우수함
Conclusion
- 벤치마크의 경우 훈련 테크닉을 잘 맞추면 어느정도 성능을 보장할 수 있어서 맹목적으로 극찬하기는 어렵습니다.
- 하지만, 그리 복잡하지 않은 chain과 각 task별로 통합된(unified) 형태로 AI Agent를 구성했다는 점은 인상깊습니다.
References
Miscellaneous